
AI Phone:先是芯片,再是模子,临了才是手机厂商

文 | aiAR掂量媛
卖铲子比较簇拥去淘金,永久是更好的弃取。
在大模子风靡全球、蕴含极大贸易价值的今天,「先进铲子」之间的竞赛,正趋向尖锐化。
大模子期间的掘金铲子:AI计较加快芯片如今的AI计较加快芯片头晕眼花。GPU、NPU、TPU、VPU,新想法层见叠出,手机 SoC、PC 科罚器、车端智驾和座舱芯片、高性能 AI 计较大边界工作器集群,AI 计较加快确实无处不在。
然则换汤不换药,按计较的通用性,AI 计较能够不错分为 CPU、GPU、FPGA、和 ASIC(NPU/TPU),按使用场景,不错分为测验芯片、云表推理芯片和边际侧的推理芯片。咱们知谈 CPU 治服传统的存储-箝制-运算的冯·诺依曼架构,中枢是存储要领/数据,串行法律施展实行。
CPU 的架构需要大皆的空间去抛弃高速缓存单位和箝制单位,当代 CPU 在分支瞻望和乱序实行上的要求更高,束缚新增的长指示集更进一步强化了复杂的逻辑箝制单位,比较之下 CPU 计较单位只占据了很小的一部分。大边界并行计较方面,CPU 自然的效率很低,更符合科罚复杂的逻辑箝制和通用计较。
与 CPU 比较,GPU 80% 以上的晶体管面积皆是计较中枢,即 GPU 领有相配多的用于数据并行科罚的计较单位,不错高效开动物理计较、比特币挖矿算法等。GPU 还不错为两种,一种是主要搞图形渲染的,咱们熟谙的 GPU(游戏)显卡;另一种是主要搞计较的,叫作念 GPGPU,也叫通用计较图形科罚器(科学计较),A100、H100 便是代表。GPGPU 芯片去掉了针对图形渲染的专用加快硬件单位,但保留了 SIMT(单指示多线程)架构和通用计较单位,计较的通用性更强,不错适用于多种算法,在好多前沿科学计较边界,GPGPU 是最好弃取。
FPGA 是一种半定制芯片,手脚无邪可编程的硬件平台,同期具有较高的计较性能和可定制性,芯片硬件模块、电路筹画更为无邪,但漏洞是专用 AI 计较的效用比 ASIC 差一些。
ASIC 是一种为特场地针而筹画的芯片(全定制),凭证特定算法定制的芯片架构,算力刚毅,但专科性强缩减了其通用性,算法一朝改换,计较能力会大幅下落,需要再行定制。咱们知谈的 NPU、TPU 便是这种架构,皆属于 ASIC 定制芯片。
CPU、GPU、NPU 架构区别如下图,CPU 最为平衡,不错科罚多种类型的任务,各种组件比例适中;GPU 则减少了箝制逻辑的存在但大皆增多了 ALU 计较单位,提供给咱们以高计较并行度;而 NPU 则是领有大皆 AI Core,这不错让咱们高效完成针对性的 AI 计较任务。
GPU 比较 CPU 有更多的并行计较中枢 PU 比较 CPU 和 GPU,有大皆非常进行大矩阵乘法和卷积运算的 AI Core
PU 比较 CPU 和 GPU,有大皆非常进行大矩阵乘法和卷积运算的 AI Core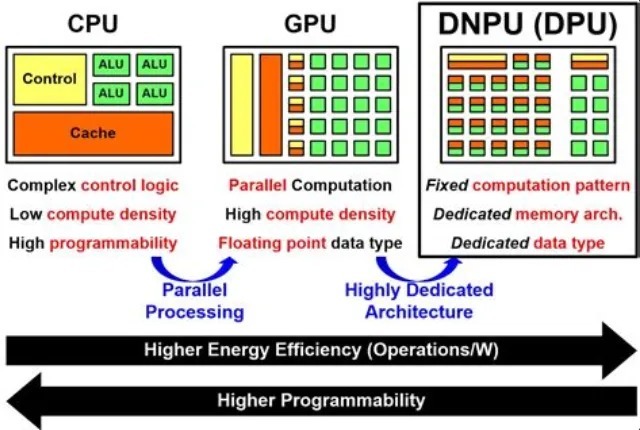
ASIC 想想下的 AI 芯片手脚一种专用科罚器,通过在硬件层面优化深度学习算法所需的大矩阵乘法、张量运算、卷积运算等重要运算,不错显赫加快 AI 应用的实行速率,缩小功耗。与在通用 CPU 上用软件模拟这些运算比较,AI 芯片能带来数目级的性能普及。因此,AI 芯片已成为如今大模子测验和推理的重要载体。
AI 专用科罚器的发展最早不错追忆到 2015 年。2015 年 6 月,谷歌 I/O 开采者大会上推出第一代神经网罗计较专用芯片 TPU,非常用于加快 TensorFlow 框架下的机器学习任务。区别于 GPU,谷歌 TPU 是一种 ASIC 芯片决策,一般来说 ASIC 芯片开采时候长、研发资本高,工作于专用计较,兑现的卑劣任务较为固定和短促。而后,谷歌又陆续推出了多个 TPU 系列产物,束缚优化其架构和性能。
终局推理侧的AI芯片:AI Phone的重要能力尽管 AI 芯片的种类、兑现的任务和部署形式各种且复杂,但其功能最终不错归结为两种:测验和推理。
在测验阶段,AI 芯片需要复古大边界的数据科罚和复杂的模子测验。这需要芯片具有刚毅的并行计较能力、高带宽的存储器探问以及无邪的数据传输能力。NVIDIA 最新的 H100 GPU、华为昇腾 Ascend NPU、谷歌 TPU 等非常为 AI 测验筹画的芯片,领有超强的计较能力、超大显存和极高的带宽,能够科罚海量数据,超过符合测验肖似 GPT 等大讲话模子。
在推理阶段,AI 芯片需要在功耗、资本和及时性等方面进行优化,以讲理不同应用场景的需求。云表推理常常对性能和费解量要求较高,因此需要使用高性能的 AI 芯片,边际和端侧推理对功耗和资本愈加明锐,因此需要使用低功耗、低资本的 AI 芯片,如非常为桌面、挪动和镶嵌式树立筹画的 NPU等。
英特尔最新的酷睿 Ultra 旗舰科罚器,基于 x86 平台的异构AI计较,集成的 GPU 和 NPU 性能越来越高。高通和 MediaTek 最新的高端挪动科罚器,针对不同任务的 AI 计较加快,统共这个词 SoC 微架构上,NPU 的迫切性也越来越凸起。
相较于测验芯片在云表成为某种“基础设施”,端侧的推理芯片则站在了 AI 应用的前沿。将测验好的模子为执行全国提供智能工作,超过是现在也曾成为“个东谈主信息Hub”的手机终局,某种预见上也曾成为了平凡东谈主新孕育出来的器官,当大模子与手契机通,不依赖网罗和云表算力就能让手机具备大模子能力,AI Phone 的贸易遐想力浩大。
高通 VS MediaTek ,最新的挪动旗舰芯片大模子推理正在向手机、PC、智能汽车等终局渗入。但是,在终局部署 AI 大模子时,仍濒临着多模态模子压缩、存储与计较瓶颈、数据传输带宽箝制、模子 always-on 树建功耗和发烧、软硬件连合调优等多重挑战。超过是在手机端,芯片必须在保证高性能的同期,尽量缩小功耗,这要求芯片筹画在硬件架构和算法加快技能上进行优化,以提高计较效率并减少动力遽然。
以高通最新的骁龙旗舰芯片为例,“为了兑现更快的 AI 推感性能,高通普及了统共(AI计较)加快器内核的费解量,还为标量和向量加快器增多了更多内核,讲理增长的生成式AI运算需求,尤其是面向大讲话模子(LLM)和大视觉模子(LVM)用例,以在科罚过程中复古更长的高下文。至于大家眷注的能耗,高通此次将每瓦特色能提高 45%。终局愈加高效,不需要大皆遽然电板续航。”
凭证高通的官方描写:高通最新的旗舰挪动芯片,骁龙 8 至尊版初度遴荐了一系列起始技能,包括第二代定制的高通 Oryon CPU、全新切片架构的高通 Adreno GPU 和增强的高通Hexagon NPU,能够为用户带来终局体验的全面改造。手脚高通迄今为止最快的CPU,Oryon CPU 领有 2 个主频高达 4.32GHz 的超等内核和 6 个主频 3.53GHz 的性能内核。其单核性能和多核性能比较前代均普及了 45%,浏览器性能普及了 62%,可为大皆的多任务科罚、速即网页浏览和疾速游戏反馈体验提供刚毅的性能和能效复古。同期,骁龙8至尊版还复古高达 10.7Gbps 速率的 LPDDR5X 内存,为用户带来更为丰富的终局侧 AI 使用体验。
基于全新的高通 Hexagon NPU,骁龙 8 至尊版初度复古终局侧个性化多模态 AI 助手,能够赋能边界更大且愈加复杂的多模态生成式 AI 用例在终局侧高效开动。在科罚器上,高通 Hexagon NPU 增多了迥殊内核,领有 6 核向量科罚器和 8 核标量科罚器,能够进一步讲理生成式 AI 运算束缚增长的需求。
 收获于在软件上的束缚优化、Hexagon NPU 新增的科罚器中枢以及多模态模子,骁龙 8 至尊版能兑现更快的 AI 科罚速率。其 AI 性能普及了 45%,每瓦特色能普及 45%,并复古 70+ tokens/sec 的输入,用户不错上传更大的文档、音频和图像,让手机在科罚复杂任务时能够愈加笔底生花。
收获于在软件上的束缚优化、Hexagon NPU 新增的科罚器中枢以及多模态模子,骁龙 8 至尊版能兑现更快的 AI 科罚速率。其 AI 性能普及了 45%,每瓦特色能普及 45%,并复古 70+ tokens/sec 的输入,用户不错上传更大的文档、音频和图像,让手机在科罚复杂任务时能够愈加笔底生花。
有了全新 Hexagon NPU 的复古,不管是在拍照时的智能识别与优化,照旧游戏中的及时渲染与计较,骁龙 8 至尊版皆能为用户提供刚毅的 AI 引擎复古,匡助用户能够遍地随时开启灵感全国,创造无穷可能。在影像科罚能力上,通过 AI-ISP 和 Hexagon NPU 的深度会通,骁龙 8 至尊版可带来破损性的拍摄体验,让用户在拍照时得到更多的AI加执,其复古 4.3GP/s 像素科罚能力,数据费解量比较上代普及了 33%,能够复古三个 4800 万像素图像传感器同期进行 30fps 视频拍摄。
骁龙 8 至尊版复古无穷语义分割功能,不错对图像进行跨越 250 层语义识别和分割,针对性优化图像中的每个细节。在无穷语义分割基础上,骁龙 8 至尊版的及时皮肤和天外算法不错诈骗 Hexagon NPU 来识别光辉条目并进行修图,即使在光辉条目不及的情况下,也能拍出具有当然成果的皮肤和天外色彩。
基于Hexagon NPU,骁龙8至尊版还复古及时 AI 补光技能,让用户即使在近乎暗中的环境下,也能生动纪录 4K 60fps 的视频。在视频通话或者直播时遭遇背光情况,及时 AI 补光技能仿佛增多了一个臆造的可挪动光源,让用户时刻皆能展现我方好意思好的一面。在刚毅算力的复古下,骁龙 8 至尊版还复古视频魔法擦除功能,用户不错径直在视频中弃取需要擦除的对象将其摈弃,而无需将视频上传到云表。
此外,骁龙 8 至尊版还领有 AI 宠物拍摄套件,能够明晰纪录萌宠们“放飞自我”的狡滑时刻,不管是快速奔波照旧嬉戏打闹,皆能被精确捕捉。
在高通发布骁龙 8 之前,多年蝉联手机挪动芯片阛阓份额第一的 MediaTek,也在最新的天玑 9400 旗舰芯集成 MediaTek 第八代 AI 科罚器 NPU 890,在其复古下,天玑 9400 复古时域张量(Temporal Tensor)硬件加快技能、端侧高画质视频生成技能,赋能端侧开动 Stable Diffusion 的性能普及了 2 倍,不仅能够兑现高差异率生图,更复古端侧动图和视频生成,兑现更多新玩法。
凭证 MediaTek 官方描写:天玑 9400 领有强悍的端侧多模态 AI 运算性能,科罚能力高达 50 tokens/秒;开动各种主流大模子,平均功耗可节俭 35%,为手机终局用户带来更聪惠、更省电的 AI 智能体互动。跟着大讲话模子能力的普及,智能体多轮对话与复杂场景的判断需求越来越迫切。天玑 9400 已能复古到至高 32K tokens 的文本长度,是上一代的 8 倍! 为了强化端侧模子的数据安全和个东谈主秘籍作用,MediaTek 天玑 9400 复古端侧 LoRA 测验,毋庸传贵府上云,每位用户在端侧就不错宽心享受及时的个性化测验与生成,还可用个东谈主相片创建各种画风的数字形象,并更换各种姿势和配景,让秘籍更安全。
为了强化端侧模子的数据安全和个东谈主秘籍作用,MediaTek 天玑 9400 复古端侧 LoRA 测验,毋庸传贵府上云,每位用户在端侧就不错宽心享受及时的个性化测验与生成,还可用个东谈主相片创建各种画风的数字形象,并更换各种姿势和配景,让秘籍更安全。
不管云表模子照旧端侧大模子,骨子是“一堆参数”。手机终局实行大模子推理的过程:用户输入文本(教导词,也即常说的 Prompt)编码转动为向量,内存加载参数,激活参数实行 AI 计较,输出向量解码。
 大模子推理的基本经由,用户提供一个 prompt(教导词),手机开动的推理框架凭证输入的教导词生成回复。推理过程常常分为两个阶段:prefill 阶段和 decoding 阶段。在 Prefill 阶段,内存加载模子参数,推理框架接录取户的教导词输入,然后实行模子参数计较,直到输出第一个 token。这个阶段只开动一次,耗时较长。
大模子推理的基本经由,用户提供一个 prompt(教导词),手机开动的推理框架凭证输入的教导词生成回复。推理过程常常分为两个阶段:prefill 阶段和 decoding 阶段。在 Prefill 阶段,内存加载模子参数,推理框架接录取户的教导词输入,然后实行模子参数计较,直到输出第一个 token。这个阶段只开动一次,耗时较长。接下来是 Decoding 阶段,这个阶段是一个自记忆的过程,每次生成一个 token。具体来说,它会将上一时刻的输出 token 手脚刻下时刻的输入,然后计较下一时刻的 token。若是用户的输出数据很长,这个阶段就会开动好屡次。Decoding 阶段的 Token 费解率,即常说的推理速率 XXToken/sec。
若何评价不同品牌的AI Phone 的大模子开动性能的优劣?开动相似参数尺寸(比如3B)的端侧模子,模子的“学问密度”相易的情况下,Prefill 阶段的首 Token 延长,以及 Decoding 阶段 Token 生成速率是两个最直不雅的方针,它径直反馈一款AI Phone开动大模子是否通顺,用户体验感知最澄清。虽然 AI Phone 开动模子时的内存占用压缩,量化精度赔本,AI Phone 开动的多模态模子和文本基座模子本人的性能和功能,模子层的优劣影响亦然决定性的。一个高效压缩、功能全面、性能强悍、跨算力平台兼容性好的端侧模子,还莫得公认的最强人。
现在,AI Phone 算力芯片复古的推理框架,适配优化复古的模子种类和数目,正在肉眼可见的增长和兴盛。端侧模子开动在不同终局,针对不同 ASIC 芯片 NPU 的兼容,进行 AI 计较硬件加快和报复优化的空间还相配大,这是一个触及终局厂商、芯片厂商、模子厂商三方的生态构建。谁能提前布局,不辞繁忙更多作念幕后看不到的“有效功”,大模子期间它一定赢得阛阓的“加快”。




